I’m teaching an intro calculus class this year (specifically, ‘Math for Life and Social Science’), and came a while ago to the section on optimization. It’s a really important subject, and yet the optimization problems one finds in Calculus books (even good ones) tend to be contrived examples which I refer to as ‘box factory problems.’ Things along the lines of ‘minimize the surface area of a rectangular box with volume 

These are fine for a problem or two: There’s a useful skill in taking a real-sounding problem and translating it into the mathematics you’re learning. We use the constraints (in this case, on the volume) to reduce the number of dimensions, turn the problem into a one-variable calculus problem, and then solve. All well and good, but these problems somehow completely miss the impact of optimization on society at large. Largely because the optimization problems that occur most commonly in the wild have a slightly different flavour.
Problem: In Boston, we observe that the monthly rent for three one-bedroom apartments are $1300, $1150, and $950. Rent on three two-bedroom apartments were $1500, $1700, and $1200. Assuming that the cost of a 0-bedroom apartment is $500, find the best possible line describing the rent as a function of the number of bedrooms. Continue reading

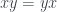 for any x, y.
for any x, y.







