This was a bit different from other Kaggle competitions. Typically, a Kaggle competition will provide a large set of data and want to optimize some particular number (say, turning anonymized personal data into a prediction of yearly medical costs). The dataset here intrigued me because it’s about learning from and reconstructing graphs, which is a very different kind of problem. In this post, I’ll discuss my approach and insights on the problem.
I’ve finally had a bit of time to finish up the code for the Rock-Paper-Scissors bot discussed in the previous posts; I’ve put the code in a GitHub repository here. Feel free to file issues if you would like it to be a bit more user friendly.
Win percentage over time, Diaconis vs Switchbot. As time increases, the win percentage settles in on 2/3’s which is a natural limit for play against Switchbot.
The bot which uses the Fourier transform on move probabilities to search for profitable patterns is named `diaconis`, after Persi Diaconis. It’s currently working just fine, but is a bit slow computationally. On startup, it generates all possible move patterns that it will investigate during the course of each game, as well as some character tables. After each play, it tests some of these patterns, and tries to determine if their predictive power is better than any of the patterns seen thus far. If so, it begins using that pattern to choose move probabilities.
This works fine as a proof-of-concept of the basic ideas. Additional improvements could be had by doing some code optimization to speed things up a bit, and keeping a list of good patterns and allowing a bit more dexterity in switching between the patterns used for prediction.
I’ve recently been doing some reading on machine learning with a mind towards applying some of my prior knowledge of representation theory. The initial realization that representation theory might have some interesting applications in machine learning came from discussions with Chris Olah at the Toronto HackLab a couple months ago; you can get interesting new insights by exploring new spaces! Over winter break I’ve been reading Bishop’s ‘Pattern Recognition and Machine Learning‘ (slowly), alongside faster reads like ‘Building Machine Learning Systems with Python.‘ As I’ve read, I’ve realized that there is plenty of room for introducing group theory into machine learning in interesting ways. (Note: This is the first of a few posts on this topic.)
There’s a strong tradition of statisticians using group theory, perhaps most famously Persi Diaconis, who used representation theory of the symmetric group to find the mixing time for card shuffling. His notes ‘Group Representations in Probability and Statistics‘ are an excellent place to pick up the background material with a strong eye towards applications. Over the next few posts I’ll make a case for the use of representation theory in machine learning, emphasizing automatic factor selection and Bayesian methods.
First, an extremely brief overview of what machine learning is about, and an introduction to using a Bayesian approach to play RoShamBo, or rock paper scissors. In the second post, I’ll motivate the viewpoint of representation by exploring the Fourier transform and how to use it to beat repetitive opponents. Finally, in the third post I’ll look at how we can use representations to select factors for our Bayesian algorithm by examining likelihood functions as functions on a group.
A quick game of Go with Yan X Zhang at the Sage-Days in Orsay. I lost badly!
Back for a day in Nairobi after visiting Paris for FPSAC 2013 and Sage-Days 49. On the whole, it was a really productive visit; I met a number of my primary goals. On the mathematics front, Kenya has been extremely isolating: One of the big goals for the conference, then, was to connect to some new things to work on and figure out what’s been happening in the algebraic combinatorics world in the last year. It was exciting to actually work on math with people: when I arrived in Maseno, it turned out that no new graduate students had come into pure maths in some time, which meant there was no real outlet for doing math with other people. So it’s been kind of a lonely year: I did a lot of work on education, and did some interesting community building around computer science with LakeHub, but often felt like my big area of expertise really wasn’t terribly helpful in Kenya. The institutions weren’t really ready to make use of what I was bringing, since there wasn’t time or space for people to do research. I obviously found lots of great stuff to work on anyway, but it felt a bit funny that I was so unable to engage people on the maths.
Layout of resources for a hypothetical Sage problem server.Django
Problem Statement.
I’ve finally been making some progress towards building a Sage-based ‘problem server,’ as we were talking about way back in January. It’s clear that the tools developed have a wide scope of use. Before building something that gives open questions and reacts in really interesting ways to input, a stepping-stone is to build something that serves up individual math problems and asks for an answer. In some sense, such things are already done by Webwork and Moodle with varying degrees of success, but building a nice implementation would allow some new directions.
Now, I should stress that I think WeBWorK is pretty awesome, and has some really transformative potential. I’ve been encouraging its use in Kenya, and it’s been extremely interesting seeing it used in service courses in Strathmore University and now Maseno. These are places with ever-increasing class sizes, and a well-designed online homework tool promises to greatly improve student comprehension of the course material. The big database of existing problems in WeBWorK is also really helpful; there are over 26,000 problems in the Open Problem Library. There are three issues with WeBWorK that a new implementation could/should address:
Modularity: WeBWorK is a pretty monolithic piece of software. It includes three essential components: a problem server, a problem database, and a learner management system (LMS). Basically, these should be busted out into three genuinely separate components. Breaking out the problem server allows easy integration into Moodle or another well-thought-out LMS, or else integration directly into things like online textbooks.
Modernization: The WeBWorK codebase was mainly developed some time ago, and new versions are slow to come out. (The last stable release is from December, 2010, over two years ago.) The interface is also decidedly… Clunky. There’s a natural question of how one could improve the system using modern AJAX-type tools. Better interactivity will lead to a much better user experience. Things like one-button signup with Google or Facebook accounts is one thing I can think of off the top of my head that would greatly improve the user experience.
Ease of Writing Problems: Currently, WeBWorK problems are written in a highly idiomatic version of Perl. I was interested in writing problems a couple years ago and got the feeling that it was, in the end, a bit of a black art. The documentation is a bit scant, and most mathematical objects have their own idiomatic libraries. Switching to a python/sage framework would mean that writing problems should become much easier: Sage already recognizes all of these mathematical structures. And if the problem definitions are in python, we’re really using the same syntax as our Sage work. This should make it much, much simpler to pick up a bit of Sage and then start writing problems.
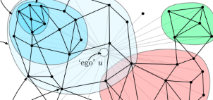 This week I was surprised to learn that I won the Kaggle Social Networks competition!
This week I was surprised to learn that I won the Kaggle Social Networks competition!



