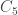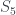In the last two posts, we’ve looked at using machine learning for playing iterated Roshambo. Specifically, we saw how to use Bayes’ theorem to try to detect and exploit patterns, and then saw how Fourier transforms can give us a concrete measurement of the randomness (and non-randomness) in our opponent’s play. Today’s post is about how we can use representation theory to improve our chances of finding interesting patterns.

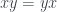 for any x, y.
for any x, y.
A Crash Course in Group Theory
I’m going to attempt to run through a few of the basic ideas of group and representation theory now without writing a full textbook. There’s a huge amount of additional information out there; this is just enough to explain what I’m doing with Roshambo, and hopefully get you interested in learning more if you’re not already a mathematician!
Groups are mathematical structures that measure symmetry in a system. They show up all over the place, really anywhere where there’s symmetry. Some groups are finite, like the symmetries of a cube, and some groups are infinite, like the symmetries of a sphere. There’s an abstract mathematical definition of a group which doesn’t really care so explicitly about the notion of symmetry, but the most important groups usually do arise as symmetries of important geometrical objects. One of my favourite groups is the group of permutations, 
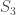

Symmetries can be composed to get other symmetries. Thinking of a equilateral triangle, rotation by 120 degress is a symmetry, as is flipping the triangle over. If I rotate and then flip, I get another symmetry of the triangle. Groups always have this kind of composition: Put together two elements of a group (ie, symmetries), and you get another element (symmetry) back.
Representation theory is, roughly speaking, the study of how mathematical groups show up in the world. Technically, a representation is an action of a group on a vector space: an expression of symmetry of the vector space that encodes at least some of the symmetry of the group; representation theory is the study of such actions. I identify vector spaces with ‘the world’ because, as scientists and mathematicians, we tend to linearize everything as quickly as possible, so that interesting group actions on a system usually translate into linear representations.
It turns out that for any finite group (like symmetries of a polygon or permutations or a finite cyclic group, like 
There are also analogues of the Fourier transform for certain infinite groups. The ‘circle group’ corresponds to the usual continuous Fourier transform, but other important groups like the group of four-dimensional orthogonal matrices have interesting representation theory as well, and thus a notion of a Fourier transform.
In general, it’s very difficult to find all of the irreducible representations of a finite group. But if the group is commutative it’s pretty easy to write down all of the irreducibles, and we also know how to write down the irreducible representations of the permutation group, as well as for many of the important infinite groups.
Group Theory In Probability and Statistics
Group theory becomes useful to us in statistics and probability when there are symmetries in our space of possible data. A classic example is if you’re taking a political survey and ask respondents to give a ranked list of the presidential candidates. The possible data is any permutation of the candidates; thus, there is a permutation group’s worth of symmetry available to us. Taking the actual survey will give us a function on the permutation group: For each permutation, keep track of the number of people who gave that response. Breaking up that function according to irreducible representations will then tell us quite a bit about our voting population, in much the same way that a Fourier transform tells us about a music sample. (In fact, here’s a great paper on how to apply representation theory to voting theory; in less than twenty pages they re-prove many of Arrow’s famous theorems which were famously difficult to derive.)
A classic example of the use of group theory in statistics was Persi Diaconis’ analysis of card shuffling (and other random processes). It was long known that shuffling eventually mixes up your cards well; Diaconis used representation theory of the permutation group to show that it takes about seven shuffles. The methods he developed apply to a wide variety of other ‘mixing time’ problems, and ideas can be extended to other contexts in statistics quite easily. (The idea in a nutshell: The Fourier transform on groups gives us a way to measure distance of a probability distribution from the uniform distribution. Repeatedly applying a random process (like shuffling cards) corresponds to taking the convolution product of the function with itself; we can then measure the distance of repeated shuffles from the uniform distribution, and find a concrete place at which this distance is close to 0.)
Machine learning is essentially weaponized applied statistics: Given silly large piles of data, how can we work the existing tools of statistical modelling into computer algorithms that can operate at scale? Numerous algorithms have been developed for machine learning, and approaching a problem involves both identifying an algorithm that applies well to your use-case, but also cleaning up and choosing data to make it as easy as possible for the algorithms to succeed. In fact, improving data quality often has as much impact on the outcome as choice of algorithm. One of the main lessons learned from group theory in statistics is that recognizing symmetries in the space of data improves our ability to analyze a problem, and thus, to learn.
Distance from Uniformity
There are a number of precise ways that recognizing group structure in our data can help us out.
As mentioned in the last post, we can evaluate easily whether the data is uniformly distributed. This means we need to measure the distance between the observed probability and the uniform distribution. Diaconis uses the variation distance, given by 
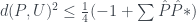
In our RPS game, this can give us an easy way to evaluate whether we’re observing a pattern, and also opens us up to evaluating whether the pattern we’re observing is significant, relative to the amount of data we’ve collected. I’ve mainly been using the former method in writing my RPS algorithm: Given the games we’ve played so far, look for non-uniform distributions and then use them to choose plays.
Here’s an example. SwitchBot plays RPS by choosing uniformly at random a move that is different from its last move. So if its last move was rock, it will play paper or scissors at random. After playing 1000 rounds, the Bayesian estimate for the distribution of moves might look like this:
{'p': [173, 1, 167], 'r': [1, 169, 165], 's': [161, 170, 1]}
This says that, for example, if ‘p’ (or paper) is played, we’ve observed 172 instances of rock and 166 instances of scissors as the next move (remembering that we initialize the algorithm with one instance each of every possible combination of prior move and next move). The probability of rock given that the last move is paper is then estimated as 
If we take a Fourier transform of 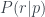

For the sake of comparison, let’s see what happens with the player who always throws rock. In this case, we get this dictionary after a thousand plays:
{'r': [999, 1, 1]}
The Fourier transform for 
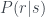
Extending to Bigger Groups
Here are two questions we can ask which will lead to looking at representations of bigger groups:
- How evenly distributed is the data?
- What if we have to declare throws (say) three at a time, instead of playing one round at a time?
Suppose we’re looking at combinations of three moves at a time to try to predict the next move. There are 27 possible data states to consider; how uniformly distributed is the data we’ve seen so far? To answer this, we can find the distribution 

Another way to extend to bigger groups is to play a variant in which we need to choose three moves ahead of actually playing them. In this case, we need to predict the probability of a given triple of plays given past data: The same kind of Fourier transform that we used to measure the distribution of data in the simple RPS game will now be of use for making predictions in this game. The algorithm works exactly the same, but now we have a larger group to work with.
We can also consider another extension of the game: Suppose we play Rock-Paper-Scissors-Lizard-Spock (an extension to