I’m teaching an intro calculus class this year (specifically, ‘Math for Life and Social Science’), and came a while ago to the section on optimization. It’s a really important subject, and yet the optimization problems one finds in Calculus books (even good ones) tend to be contrived examples which I refer to as ‘box factory problems.’ Things along the lines of ‘minimize the surface area of a rectangular box with volume 

These are fine for a problem or two: There’s a useful skill in taking a real-sounding problem and translating it into the mathematics you’re learning. We use the constraints (in this case, on the volume) to reduce the number of dimensions, turn the problem into a one-variable calculus problem, and then solve. All well and good, but these problems somehow completely miss the impact of optimization on society at large. Largely because the optimization problems that occur most commonly in the wild have a slightly different flavour.
Problem: In Boston, we observe that the monthly rent for three one-bedroom apartments are $1300, $1150, and $950. Rent on three two-bedroom apartments were $1500, $1700, and $1200. Assuming that the cost of a 0-bedroom apartment is $500, find the best possible line describing the rent as a function of the number of bedrooms.
Solution: We observe that a line through the data is of the form 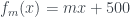


To find the best choice of m, we should then try to minimize the error function. We do this by (as usual) differentiating with respect to m, setting the derivative equal to zero, and solving. In this case, we get (after expanding the polynomial in the data):

so then taking the derivative and solving for m, we get 
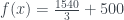
This kind of problem does a few things nicely.
- We apply our knowledge of using the derivative to find extrema, which is the main goal of this section of the course.
- We see an extremely common special case for a problem that extends in many different ways. It’s immediately obvious that there’s a choice for the intercept, and that changing the intercept will yield different answers. This gives an immediate extension to a multi-variable problem, giving good motivation for later material. The particular book I’m using (Neuhauser) also develops linear algebra before multivariable calculus; it’s very well set up for doing simple least squares regression.
- It undercuts one of the ‘big lies’ of basic calculus. Often in calculus class, we have a lot of information about the various derivatives of a function; in applications, this requires quite exact information about an observation at a very particular point in time. In life, though, we usually have many noisy data points and have to try to reconstruct a function.
- Neuhauser is full of modelling problems, where you’re given a particular form of equation (with some constants) and told that it models (say) gopher populations. This method gives the students an idea of how to go about actually finding the constants in these models to try to fit actual data.
- You get an extremely good idea of why computers are important in modern science. This problem, as stated, is terrible to do by hand. On quizzes, I give the students at most three data points to work with. But we can use Sage for the tedious part quite easily:
sage: D=[(1,1300),(1,1150),(1,950),(2,1500),(2,1700),(2,1200)]
sage: m=var('m')
sage: E=sum([ (m*b+500-p)^2 for (b,p) in D ])
sage: E.expand()
15*m^2 - 15400*m + 4195000I try hard to impress upon students that what matters is picking up enough of a conceptual framework to be able to recognize problems, solve small cases by hand, and work with computers to solve large cases.
- Finally, there’s a conceptual leap here where we recognize the constant m as a variable itself; we (probably for the first time for the students) deal with a family of functions.
From here, it would be interesting to see if there are any of Neuhauser’s modelling problems that could be fit into regression problems to find constants that would be easy enough for a first year calculus student to finish. One could also look at doing some simple classification problems, which involve working with sigmoid functions and some interesting derivatives.

One thought on “Escape From the Box Factory: Better Single Variable Optimization Problems”
Comments are closed.