I recently read Edward Tufte’s ‘Visualizing Quantitative Information,’ a classic book on visualizing statistical data. It reads a little bit like the ‘Elements of Style’ for data visualization: Instead of ‘omit needless words,’ we have ‘maximize data-ink.’ Indeed, the primary goal of the book is to establish some basic design principles, and then show that those principles, creatively applied, can lead to genuinely new modes of representing data.
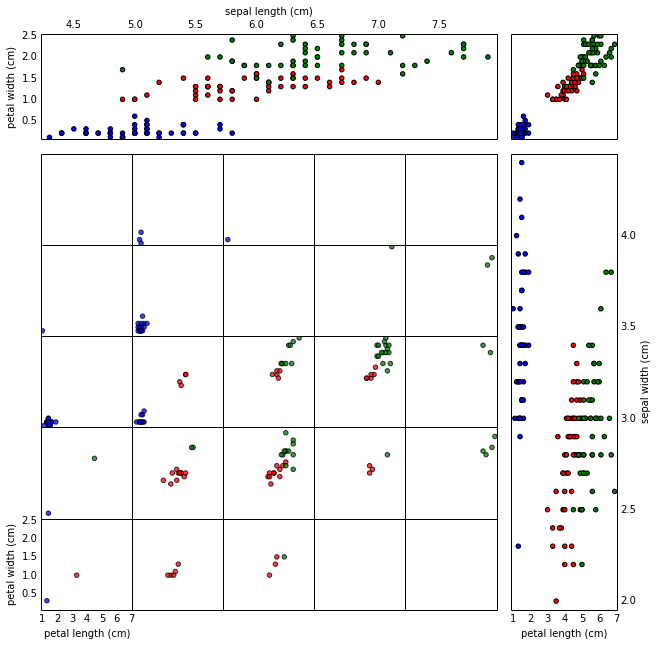
One of my favorite graphics in the book was a scatter plot adapted from a physics paper, mapping four dimensions in a single graphic. It’s pretty typical to deal with data with much more than three dimensions; I was struck by the relative simplicity with which this scatter plot was able to illustrate four dimensional data.
I hacked out a bit of python code to generate similar images; here’s a 4D scatter plot of the Iris dataset: