
Recently I’ve seen a couple nice ‘visual’ explanations of principal component analysis (PCA). The basic idea of PCA is to choose a set of coordinates for describing your data where the coordinate axes point in the directions of maximum variance, dropping coordinates where there isn’t as much variance. So if your data is arranged in a roughly oval shape, the first principal component will lie along the oval’s long axis.
My goal with this post is to look a bit at the derivation of PCA, with an eye towards building intuition for what the mathematics is doing.
Suppose we have a matrix of data X, whose rows 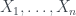
Our first job is to clean up the data a bit by removing the column means from each of the data points, so that all of the features have mean zero. We’ll call this adjusted matrix 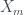
Once we’ve ‘demeaned’ the data, we compute two very important related matrices, the scatter matrix and the Gram matrix. PCA is fundamentally a way to extract important information from the scatter matrix. The scatter matrix is 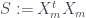
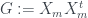

And here’s a bit of example python code:
import numpy as np
rnd = lambda x: np.round(x,2)
X=np.matrix([
[1,1,0,0],
[1,1,0,0],
[1,0,1,1],
[1,1,0,1],
[0,0,1,1],
[0,1,1,1],
])
print X
# Remove column means
Xm = X-X.mean(axis=0)
# Divide columns by their norms. Equivalent to tfidf.
# Xm=X / np.linalg.norm(X, axis=0)
print 'Column means: ', rnd(Xm.mean(axis=0))
print 'Column norms: ', rnd(np.linalg.norm(Xm, axis=0))
print 'Demeaned X:\n', rnd(Xm)
S = Xm.transpose()*Xm
G = Xm*Xm.transpose()
print 'Scatter matrix:\n', rnd(S)
print 'Gram Matrix:\n', rnd(G)
This produces the following output:
[[1 1 0 0]
[1 1 0 0]
[1 0 1 1]
[1 1 0 1]
[0 0 1 1]
[0 1 1 1]]
Column means: [[ 0. 0. 0. 0.]]
Column norms: [ 1.15 1.15 1.22 1.15]
Demeaned X:
[[ 0.33 0.33 -0.5 -0.67]
[ 0.33 0.33 -0.5 -0.67]
[ 0.33 -0.67 0.5 0.33]
[ 0.33 0.33 -0.5 0.33]
[-0.67 -0.67 0.5 0.33]
[-0.67 0.33 0.5 0.33]]
Scatter matrix:
[[ 1.33 0.33 -1. -0.67]
[ 0.33 1.33 -1. -0.67]
[-1. -1. 1.5 1. ]
[-0.67 -0.67 1. 1.33]]
Gram Matrix:
[[ 0.92 0.92 -0.58 0.25 -0.92 -0.58]
[ 0.92 0.92 -0.58 0.25 -0.92 -0.58]
[-0.58 -0.58 0.92 -0.25 0.58 -0.08]
[ 0.25 0.25 -0.25 0.58 -0.58 -0.25]
[-0.92 -0.92 0.58 -0.58 1.25 0.58]
[-0.58 -0.58 -0.08 -0.25 0.58 0.92]]
More on the Scatter Matrix
Because the scatter matrix is so important, I’m going to linger on it a bit.
Since the entries of the scatter matrix are dot products of column, we can think of them as dot products of the features that those columns represent. So the (2,3) entry compares the 2nd and 3rd feature. The dot product 
If we were to add more data points, the scatter matrix would generally have a larger norm. It seems a bit silly to be so reactive to the size of the data set; if we rescale by the number of data points we get something a bit more robust. Indeed, if you multiply the scatter matrix by 
So the scatter matrix records vital statistical data about the relationship between features in our particular dataset.
Now, the singular value decomposition of 

and
are orthogonal matrices (so that
and
are identity matrices), and
is a diagonal matrix of the eigenvalues of
(if
But if we multiply the scatter matrix by 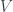
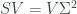

We can express 

Finally, PCA
The main idea of principal component analysis is to sort the eigenvalues 
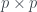

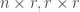

In this picture, we show the PCA obtained by keeping the two largest eigenvectors. Since the resulting data is two dimensional instead of four, we can plot it!
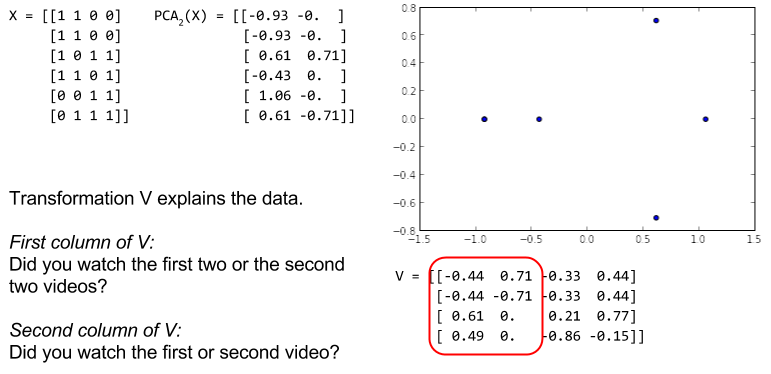
As indicated in the picture, when we squint at the columns of
The beauty of PCA is that it makes asking these kinds of questions of the data automatic: What are the combinations of features (and in what amounts) that best decompose the data set?
Additionally, to apply PCA, we only have to keep the matrix
Note that the sizes of the eigenvalues explicitly describe the contribution of each eigenvector to our dataset
Further directions – Kernel PCA
The key takeaway here is that PCA comes down to understanding the relationship between features in your dataset, as measured by a dot product. However, there are many other ways to write down a relationship than just the dot product!
For example, we can make a new scatter matrix 
You can find an implementation of kernel PCA in scikit-learn.
Further Directions – Respecting Data Segmentation
If your data naturally clusters into major segments with radically different behaviour, the standard PCA may not do a great job of describing your data. Instead, you can perform some segmentation or pre-clustering, and then apply a different PCA decomposition to each of the different data clusters.
Further Directions – Probabilistic PCA
Bishop’s Machine Learning and Pattern Recognition book describes a couple nice probability-based interpretations of PCA. The first allows computation of the PCA iteratively using an EM algorithm, which can be faster than explicitly computing eigenvectors with certain large datasets. Bishop also describes a Bayesian approach to determine the number of components one should actually keep.
