I attended a really nice talk by Arash Amini yesterday about detecting ‘communities’ in sparse graphs. The basic problem is: In a big graph (like the Facebook graph, or the graph of scientific papers citations) you have clusters of friends/associates, and you want to pick out those clusters. Dr. Amini and his collaborators have been working on methods to solve this problem in particularly noisy cases. The methods presented were developed for cases where you know the specific number of clusters you are seeking to find. It was a fascinating talk, and I came away wondering if there are good methods to use when you aren’t sure of how many clusters there are.

The adjacency matrix of a graph is just a matrix of 1’s and 0’s encoding which vertices are connected to which. If you start with a graph and number all the vertices from 1 to n, then make the matrix, you get an adjacency matrix. But of course, there are n! different adjacency matrices encoding the same graph, from reordering the labels on the graph.
A matrix is block diagonal if there are square blocks of 1’s along the diagonal and 0’s everywhere outside of these blocks. As a graph, this looks like clusters of people where everyone knows everyone inside their cluster, but no one in each cluster knows anyone from any of the other clusters. One can imagine that this would resemble a Facebook graph for pre-internet societies on isolated Pacific islands…
If we have one of these perfectly clustered graphs, there are still n! ways to write an adjacency matrix, and most of them look quite chaotic to our eyes. But some of the adjacency matrices will be obviously block diagonal. Our problem of finding communities, then, is the same as asking: “Given a block diagonal binary matrix with mixed up labels, how can I sort the rows and columns to get back to the block diagonal form?”
We’ll also want to answer this for ‘almost’ block diagonal matrices, where maybe you have some connections between clusters, and maybe some people within clusters who don’t know one another. How do we detect that structure?
Math Overflow to the Rescue
Searching the internet for answers brought up a really nice idea from Tim Gowers on MathOverflow. It’s well-known to people who know such things that if you take the p-th power of the adjacency matrix, you get a matrix whose ij-entry is the number of ways of getting from node i to node j in p steps. (The usual adjacency matrix, the first power, encodes the number of ways of getting from i to j in 1 step… ie, whether the two nodes are connected by an edge or not.)
Now, if you have a cluster of people who more-or-less know each other, there are going to be lots and lots of paths from one person to another inside the cluster. On the other hand, if you have two clusters that aren’t very connected to each other, you’ll not have many ways to move from one of those clusters to the other. So if you take a power of the adjacency matrix, the clusters show up as groups of nodes with big numbers of paths connecting them to one another.
To make this a bit more statistical-looking, we might take the adjacency matrix A, raise it to a power p, and then compute the mean value and standard deviations of each row of 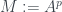
For a totally random graph, we would expect these scores to hover around 0. But in a graph with a strong block diagonal structure, we should see some spikes corresponding to the various clusters. This corresponds to deciding on some kind of a cut-off for how significant the correlation should be before deciding to include a vertex in a cluster. Gathering these clusters up, we relabel our graph, and get something roughly block diagonal.
There’s some question here of how to do the gathering of the clusters. One method would be to make a collection of favorites for each vertex, then perform a kind of iterated merge function to gather these sets of favorites into a partition of the vertices. A possibly better algorithm would be to note that the row vectors for vertices in the same cluster should be almost the same. We create a new matrix whose ij-entry is 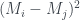
Choices, Choices…
There are two clear choices to be made in following this procedure: the power to raise the adjacency matrix to, and the cut-off threshold for deciding if two vertices should be in the same cluster.
The choice of power has a lot to do with the diameter of the various clusters – the largest distance from one member of the cluster to another. You want a high enough power that you’re able to get from any vertex in the cluster to any other vertex in the cluster easily. For clusters with lots and lots of internal connections, the diameter of the cluster will be quite low, so lower powers will be fine. In our ‘ideal’ block diagonal graph, the diameter of every cluster is 1, suggesting that it’s fine to just use the original adjacency matrix!
On the other hand, higher powers will start to see more connections to other clusters, and start counting paths within those clusters with high multiplicity. Thus, it’s probably best to get a power relatively close to the diameter of the clusters.
Meanwhile, changing the threshold will (as usual) make a fairly arbitrary choice about which vertices to include or exclude from a given cluster. A high threshold will result in smaller cluster sizes.
Evaluating Our Choices
It would be good to be able to identify the quality of a given choice of power and threshold. It turns out there’s a pretty reasonable way to do this. Our algorithm breaks up our vertices into clusters of sizes 
A perfect block diagonal matrix of shape 
More generally, we can define the block diagonal error of a matrix M to be the minimum value of
The error function 
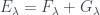
where F is the number of 1’s outside of the diagonal blocks, and G is the number of 0’s inside the diagonal blocks. There’s a refinement poset on partitions, where you break a partition up into smaller parts; the function F will always get worse when we refine a partition, and G will always get better! That’s pretty interesting, and means that we can use the refinement order on partitions as a way to search for good block diagonal structure on the matrix in a deterministic way without having to generate every possible partition in the process.
Secondly, this decomposition gives us a way to re-weight our error function according to different preferences. If we assign a higher weight to G, we’ll get bigger clusters of people who don’t necessarily know each other as well; it’s pretty easy to imagine situations where this would be useful. For example, to suggest friends in a social network, I should do some clustering and then make recommendations of people in the cluster that you don’t know; having a bigger, sparser cluster will give me more people to recommend to you.
A Very Young Algorithm
Another way to think of this from a combinatorial viewpoint is that the action of the symmetric group on a block diagonal matrix of shape 
These kinds of stabilizers are called Young subgroups, and are actually super important in the representation theory of the symmetric group. So it’s cool to see them showing up here.
Dealing with Big Data
With huge real-world data sets, doing a lot of parameter tuning might be very expensive. But if we can identify some areas of natural clustering (like, say, cities) it will give natural ways to subdivide the data to try to find good values of the threshold and power, which we can then try to use directly on our global data set.
A Final Word
Finally, I should note that Amini was trying to skirt the limit of what is possible when working with particularly noisy graphs, while this general method may not work well in limiting situations; that would take some additional work. I also haven’t done any kind of probabilistic analysis here or analysis of computational complexity. I also imagine that these methods exist in the literature somewhere; it’s a bit outside of my usual circle of reading. So please send me a link if you’ve seen any of these ideas written up more rigorously, and I’ll include the citations as I find them.
